While you can already digitize physical documents with Chrome and ChromeOS, you can’t natively get at the digital text of such scans. A new feature that will work both in Chrome and on Chromebooks will do just that. Google is adding OCR text from PDFs, whether you save them, receive them in an email, or scan them.
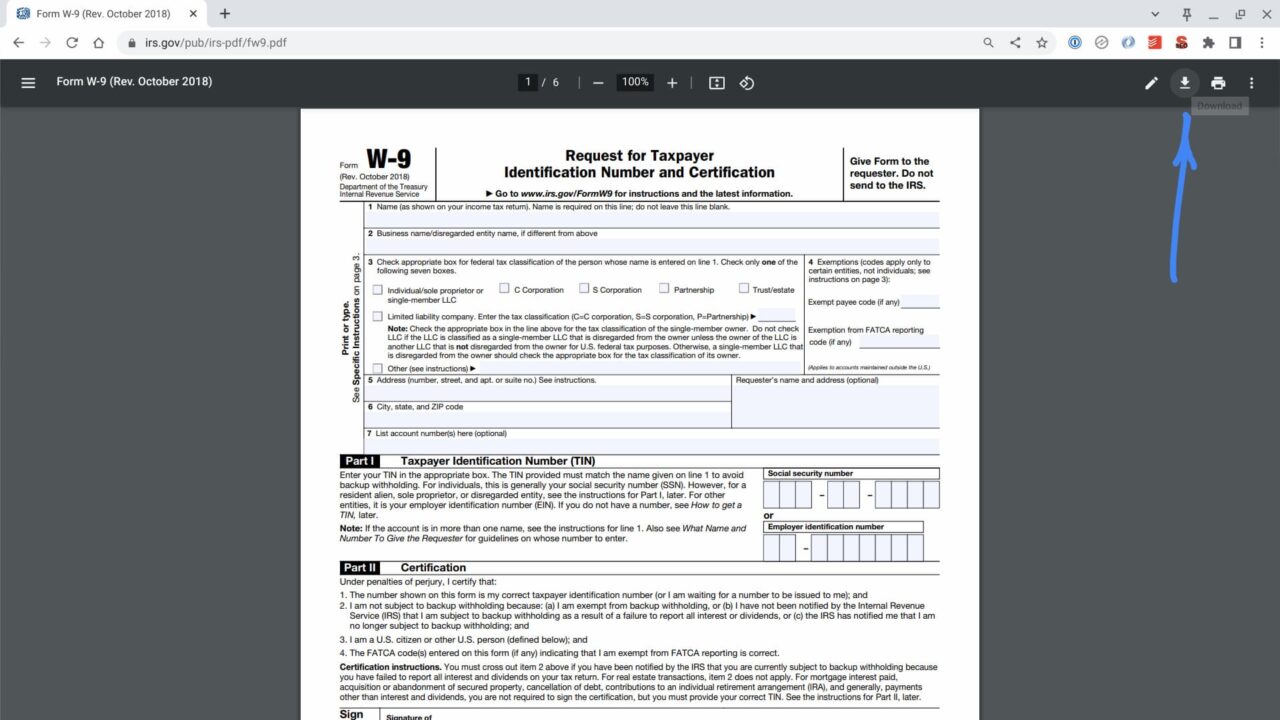
I found in-progress code for this feature in the Chromium code logs today. So you can’t yet get use OCR, or optical character regonition, from a PDF scan just yet in the browser or a Chromebook. At least you can’t on the current Stable Channel of ChromeOS, which is at version 109 since last week. I don’t yet see the feature on the Dev Channel either.
The first change I found is for a new menu option when viewing a PDF, whether it’s scanned or saved:
Add a toggle button for PDF OCR to the more action menu on PDF Viewer. This toggle button is synced with the pref for PDF OCR and sets the pref whenever it's toggled on or off.
That code led me to another change describing the user interface for PDF OCR feature although the screenshots and design documents are internal.
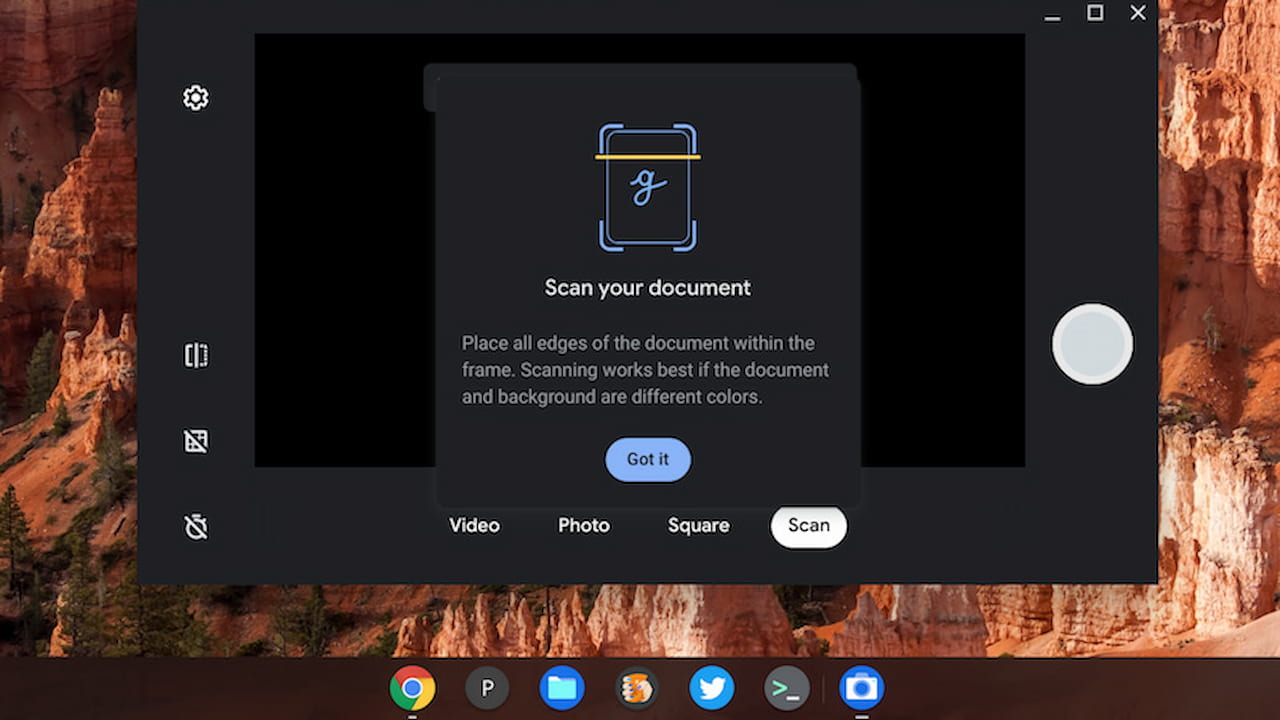
Google has quickly been beefing up digital documentation on Chromebooks of late and this is simply another step in that march forward. Last month, ChromeOS 108 added a feature that consolidates multiple document pages into a single PDF, for example. And work on the new OCR feature began a few short months ago, back in November.
I also appreciate that OCR text from PDFs is coming not just to Chromebooks but also to any device running the Google Chrome browser.
Initially, I thought this was a ChromeO-specific feature addition. However, the change log specifically references Linux, Mac and Windows systems as well. Are there good third-party options for scanning digital text from a PDF on those platforms? Sure, there are plenty. Having such a feature baked in is always nice to have, however.